Bachelor's Thesis
My Bachelor’s Thesis is titled “Inventory Forecasting in the Crude Oil Market using Natural Language Processing”, the research takes weekly U.S. Crude Oil Inventories forecasts to future inventory values using deep neural networks, incorporating inventory driver features and novel natural language features derived from breaking financial news headlines to improve forecasting. The hypothesis was that news headlines surrounding oil would enhance forecasting accuracy of US oil inventory values.
Crude oil is the most traded commodity in the world, with $1.45T being traded in 2022, thus has an enormous amount of liquidity, providing trading opportunities. The original motivation for this thesis was to find the correlation between inventory movement and market movement by forecasting the inventory ahead of time using news headlines to achieve returns from the non-linear relationship. However, my final dissertation leaned towards exploring the relationship between news neural network models, headline sentiment, and inventory values, rather than post-inventory market movement.
My research used the Energy Information Administration’s (EIA) weekly reports on crude oil inventories, which offer insights into U.S. oil supply levels on a weekly basis. I also leveraged the weekly preliminary report from the American Petroleum Institute’s (API). These weekly inventory reports help investors gauge the balance between supply and demand in the crude oil market.
The dataset is as follows: 159 weekly economic events were sampled with 25,530 headlines from FinancialJuice. A pre-trained DistilRoBERTa model that was trained on the Financial Phrasebank dataset, was used to generate aggregate time-decayed sentiment values and word embeddings, further processing was done to reduce dimensions using PCA so our models would not fall short to the curse of dimensionality. Extensive hyperparameter tuning was done using Bayesian optimisation techniques and an expanding window technique was used to ensure consistency in results of training, and showing how well the best models perform over time.
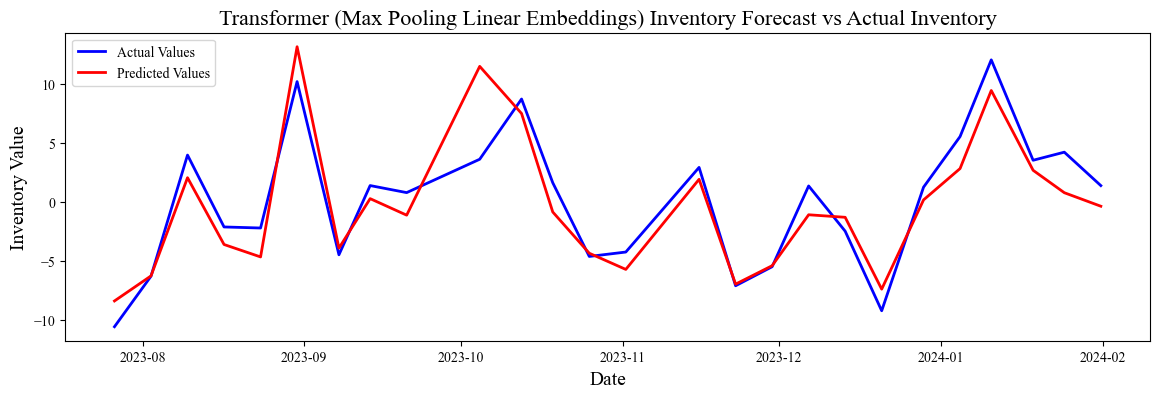
Results from the models are largely inconclusive, likely due to three things. Firstly, the nature of financial news headlines being short in text and lacking context. Secondly, the Pre-Trained model having context of the Financial Phrasebank dataset, rather than a text corpus that better represents the supply and demand dynamics of the crude oil market. Thirdly, the small sample size of 159 release events. The lowest mean squared error transformers achieved was 5.16 with PCA-reduced max-pooled embeddings with a linear dense layer. The LSTM models underperformed, this is likely due to the nature of Transformers being able to handle contextual awareness better.
There was a lot of learning to be done with this project. The scope was extensive, and I made too many assumptions on how the data would perform. In hindsight, the typical “throw a neural network at it” approach did not work well, and time would be better spent exploring the dataset and running smaller trial tests, before batch throwing lots of tensors through a neural net, and brute-forcing hyper-parameter optimisation. On this note, the signal-to-noise ratio may have been too high, by processing the textual embeddings so many times, there was not conclusive testing applied to see how effective each signal being input was, and checking if the data was becoming less effective which each embedding function being applied. Infact, the neural network without any sentiment and embeddings outperformed others.
However, this research proposes a lot of promise, as a fine-tuned time-series deep neural network model with an augmented dataset would be expected to handle the task more effectively, mitigating weaknesses of a pre-trained model, utilising the strength of models built for time-series data and using the natural language expertise of transformer neural network models. In addition, US indices are much more sensitive to news, whereas commodities are more prone to long-term macroeconomic outlooks. This study demanded significant expertise in artificial intelligence, data science, finance and statistics, all fields which I am both passionate about and aim to pursue as I progress in my career.